Non default variable chunks
maccra Feb 15 6:46AM 2018 CLI
Hello, I understand Duplicacy uses a default chunk size ration of 4, so if the default average chunk size is 4M, then the minimum chunk is 1M and the maximum chunk size is 16M (please correct if I am wrong).
But what are the pros and cons of changing this ratio e.g. average chunk size is 1M, minimum chunk size is 128 KB, maximum chunk size is 10 M.
I have a lot of small text files (50KB-200KB) that change a lot therefore my thought process in having a small minimum chuck size would reduce the number of chunks which need to be uploaded when the files change, but also most of my files (say 99%) are static and don't change at all, and they could be captured in the larger chunks.
cheers and thanks
gchen Feb 15 1:46PM 2018
You will definitely get better deduplication ratios with a smaller average chunk size. The downside is that you'll have much more chunks on the storage, which make the operations like check and prune slower.
Since your most frequently changed files are small, you aren't likely to see any deduplication effect unless you use a very small average chunk size (like 128 KB). So I guess in this case whether it is 4M or 1M doesn't matter much.
If you need to move or rename files a lot than I would suggest 1M. See a discussion on this topic here: https://github.com/gilbertchen/duplicacy/issues/334
Christoph Feb 17 5:11AM 2018
Since your most frequently changed files are small, you aren't likely to see any deduplication effect unless you use a very small average chunk size (like 128 KB)
Wasn't that precisely the question? Or rather, the question was whether it makes sense to move away from the x4 ratio and allow much smaller (as well as much bigger) chunks. The way I understood the idea is that the increase in smaller chunks would be partially compensated by a decrease in bigger chunks. Plus, you would get better deduplication effects with those frequently changing small files (though the latter probably won't save you much in terms of storage or bandwidth).
towerbr Feb 17 10:56AM 2018
Interesting, I had not thought of that: ratio ...
Perhaps, the issue is not the use of fixed or variable chunks, as in the tests I reported, but rather the relationship between minimum and maximum chunks sizes and their application in the repository.
For example, when checking file sizes (~ 11,000 files) in my Thunderbird repository, we have this:
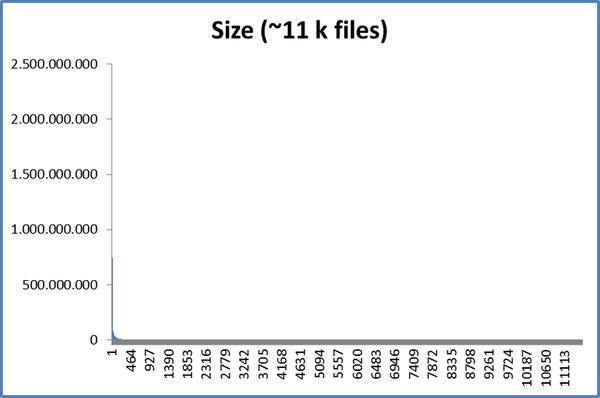
If we take only files with more than 10 Mb (183 files) we have:
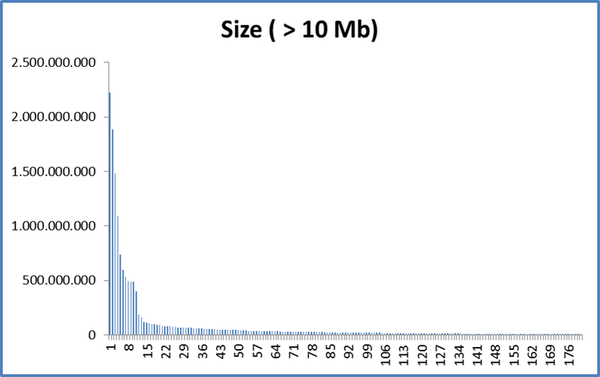
That is, there are more than 10,000 files with less than 10 Mb ...
If we also filter the files with the same patterns from the filters file, we have:
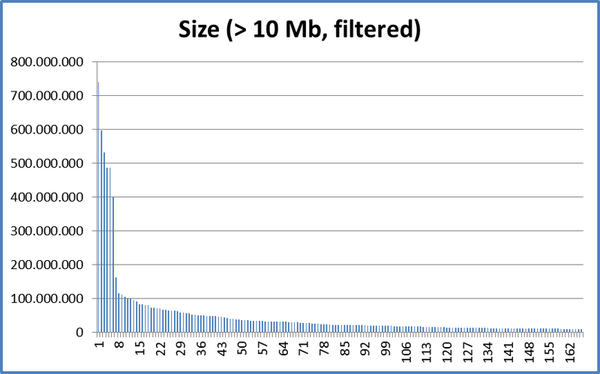
So it might be worth trying an init with a different ratio: -c 1M -min 128k -max 10M
What do you think Gilbert?
Christoph Feb 17 4:21PM 2018
@towerbr Sorry, I always have some "complaint" regarding your graphs: what are the units on your X and y axes?
@anyone_who_knows: Just a quick test if I understand the basics of chunking, could you say whether the following statements are correct, regarding these settings: c 1M -min 128k -max 10M
- if a file is smaller than 128k, more files (or file parts) will be added to the chunk until the chunk is at least 128k in size
- if a file is bigger than 128k but smaller than 10M, the file will be turned into exactly one chunk.
- If a file is bigger than 10M, it will be broken into smaller pieces, averaging 1M in size
- when deciding where exactly to cut off a slice from that big file, the content of the file is scanned in order to identify natural breaking points (e.g. if it is a zip file or some other container file, the files in the container might become chunks)
(By "a file", I obviously mean a file in the repository that is being backed up)
towerbr Feb 17 5:23PM 2018
Sorry, I always have some "complaint" regarding your graphs: what are the units on your X and y axes?
No problem, Y = size, X = the files themselves, the number means nothing, it's just a sequential automatically generated by the spreadsheet, there really should not be numbers on the X axis, but I did the graphs quickly and forgot to take them.
Christoph Feb 17 6:20PM 2018
Aha, I see. How about a graph with files size ranges on the z axis and number of files on the Y axis (i.e. showing how many files there are in each range (e.g. 0-101 kb, etc)?
towerbr Feb 17 9:12PM 2018
You are referring to a histogram. Yes, that was my initial idea, but as I did these graphs in 30 seconds, they did not turn out so good :-D .
It was an attempt to illustrate the numbers a little.
Sorry, in this case here I will not make new graphics, the summary is done:
- the repository has about 11k files;
- of these, only 183 have more than 10 Mb;
- few have more than 500 Mb;
- even these few are almost eliminated by the filter.
;-)
Christoph Feb 18 7:58AM 2018
The term "graph" has many meanings. I used it as a synonym for "chart", which includes histograms. ;-)
towerbr Feb 20 8:40AM 2018
I played a little with chunks settings and did a new test, but I'm really not sure what conclusions to take (lol): link
towerbr Feb 21 7:39AM 2018
@gchen, when you have some time I would like you to have a look at the link test above, because I had some doubts, among them:
A) Since most of the files are around 32kb, why do most chunks in the "low-threshold" test (-min 32kb) have not been generated close to that size?
B) If the Duplicacy behavior is to group the files into larger chunks as much as possible (is it?), why in the 10M upper limit test were the chunks generated in similar sizes to the 4M upper limit test?
And I repeat here the questions of @Christoph (some posts above), which represent some of my doubts too:
Just a quick test if I understand the basics of chunking, could you say whether the following statements are correct, regarding these settings: c 1M -min 128k -max 10M
1) if a file is smaller than 128k, more files (or file parts) will be added to the chunk until the chunk is at least 128k in size
2) if a file is bigger than 128k but smaller than 10M, the file will be turned into exactly one chunk.
3) If a file is bigger than 10M, it will be broken into smaller pieces, averaging 1M in size
4) when deciding where exactly to cut off a slice from that big file, the content of the file is scanned in order to identify natural breaking points (e.g. if it is a zip file or some other container file, the files in the container might become chunks)
Christoph Feb 21 10:00AM 2018
Thanks for bumping my questions. Admittedly, though, I wouldn't ask them the same way today after I learned that duplicacy currently completely ignores file boundaries. I don't know how I would ask those questions, though, because I also learned that the algorithm that determines the chunks is a bit more complicated than looking for file boundaries and watching file size. I suspect that once I read up on how that hash window thing works, my questions would become obsolete...
gchen Feb 21 11:55AM 2018
Christoph is right. Conceptually Duplicacy packs all files into a big file which is then split into chunks. It is the rolling hash algorithm that determines when to wrap up the current chunk and start a new one. The file sizes have no impact on how chunks are split.
Since most of the files are around 32kb, why do most chunks in the "low-threshold" test (-min 32kb) have not been generated close to that size?
The majority of chunks should be closer to the average chunk size (4 MB) than to the minimum or maximum chunk size.
If the Duplicacy behavior is to group the files into larger chunks as much as possible (is it?), why in the 10M upper limit test were the chunks generated in similar sizes to the 4M upper limit test?
No, the behavior is to group the files into 1MB chunks as much as possible. The similar numbers of large chunks (4MB to 10MB in your graph) mean that the upper bound of 4MB is good enough. We don't like chunks that are of exactly the maximum size because these are artificial hard limits and may be susceptible to byte insertion and deletion.
towerbr Feb 21 12:39PM 2018
Thanks! Understood.