Duplicacy vs Duplicati
gchen Jan 14 3:42PM 2018
There is an interesting discussion comparing Duplicacy with Duplicati: https://forum.duplicati.com/t/duplicati-2-vs-duplicacy-2/592
Performance wise, Duplicacy is about 2-3 times faster than Duplicati with the default settings (3:09 vs 9:07 for a small data set, and 0:27:27 vs 1:12:40 for a larger one). By disabling compression and encryption, and applying an optimization on the hash function, they were able to achieve the same or even slightly better performance (than Duplicacy with compression and encryption), but the CPU utilization was still significantly higher.
Those tests were done using one thread. Duplicacy already offers the -threads option for multithreaded uploading and downloading, while Duplicati currently doesn't, and it is unclear when it will be available.
Feature wise, Duplicati comes with a web-base UI and is more feature-complete than Duplicacy. It also has a larger number of storage backends. However, Duplicati lacks the killer feature of Duplicacy, cross-client deduplication, and it doesn't look like it will ever support it.
In my opinion, Duplicati's main problem is the use of the database and the aggressive approach to attempt to 'repair' it (as pointed out by several users in that thread). More than one new Duplicacy users mentioned that the database corruption is the main reason they gave up on Duplicati. Their developer argued that by taking an aggressive repair approach one will be able to identify storage issues sooner. In Duplicacy we took the opposite way -- we assumed that all the cloud storage can be trusted and we based our design on that. In cases where a cloud storage violates this basic assumption (for example, Wasabi, OneDrive, and Hubic), we will work with their developers to fix the issue (unfortunately not everyone is responsive) and in the meantime roll out our own fix/workaround whenever possible.
Having said the above, I applaud their collaborative efforts to start and expand such as discussion. Both sides can learn from each other and have something different to catch up on. A comprehensive and insightful comparison like this will only advance our understanding and make both software better in the long run.
kevinvinv Jan 15 10:47AM 2018
I tried duplicati before I found duplicacy and I could not get it to work easily... and the support was not very helpful (unlike duplicacy).
I dont know about the validity of trusting the storage back - end :) But we have discussed that before with a possible upcoming feature to help server side verification. Looking forward to that.
gchen Jan 15 4:52PM 2018
@kevinvinv can you submit a github issue for that feature if you haven't done so?
kevinvinv Jan 16 12:46PM 2018
Did it :) THanks.
Christoph Jan 16 3:33PM 2018
Thanks @gchen, for a fair summary of that comparison thread. Yes, this kind of open discussion is what moves open source software along (and what helps users make informed decisions).
Regarding the approach of trusting the backend, I wonder if anyone can give some indication as to what trusting implies in practice. I suspect that, despite fundamentally different approaches (trusting vs not trusting), in practice, the difference is not so big (because a lot has to go wrong before you actually lose data because you trusted). Or maybe it is? Because you do mention several providers where problems did occur. And the thing is: those are the known problems. If duplicacy trusts the storage backend by default, doesn't that already minimize the chances such problems become known (before it is too late)?
While it is clear that trusting the backend is riskier than not trusting it, I am not in the position to assess how much riskier it is. Or perhaps: under what circumstances. Anyone?
towerbr Jan 16 4:19PM 2018
As you asked for "anyone", then, my two cents:
There is no 100% fail-safe software / system, neither Dropbox, nor Duplicacy, nor Duplicati, or your NAS, and no other.
Of course there are systems theoretically more reliable than others, but in the real world you don't have easy access to system data to confirm this reliability.
So what we have to do is take actions under our control to minimize or mitigate the risks. The more measures, or more complex, the safer it gets but also more expensive.
For example: To mitigate the risk of "trusting the backend", I can periodically download random files and compare them with the production environment files. It's cheap (free), and it minimizes the risk a little.
Or I can dilute the risk by backing up to multiple destinations (can be more expensive depending on how you will set it up).
In an airplane, to mitigate risks, systems are redundant. An airplane has two or three parallel hydraulic systems. If one fails, the other system takes over. Extremely expensive, but necessary.
So in my opinion, it's not a "trusting vs not trusting" issue. The question is: how much are you willing to spend to mitigate your risk?
Christoph Jan 17 2:59PM 2018
So in my opinion, it's not a "trusting vs not trusting" issue. The question is: how much are you willing to spend to mitigate your risk?
Exactly, that is my point. In order to answer that question, you need to understand "your risk". More specifically: what kind of damage can occur, how serious is it, and how likely is it to occur. In the case of the airplane, the potential damage is quite clear: people die and it is is so high, that one is willing to accept the very high mitigation costs, even though the failure of a hydraulic system (let alone two) is quite low.
So with the backups, what might happen and how likely is it? Total data loss? Partial data loss? Corrupted data, making restore a pain?
There is no 100% fail-safe software / system, neither Dropbox, nor Duplicacy, nor Duplicati, or your NAS, and no other.
Though it is fair to mention that most cloud storage providers du have multiple redundancies across multiple data centres. So we are not really talking about that kind of loss due to hardware failure. What we need to worry about is basically software failure, like the server returning "OK" although the data has not been saved correctly. So this is basically what I'm after: what kind of software failures are we up against?
gchen Jan 17 9:55PM 2018
The "trusting vs not trusting" decision affects the implementation of backup software. If we determine the storage can be trusted, we'll just implement some verification scheme to catch the error should such an error occur, otherwise we need to implement correction (like PAR2 error correction) on top of verification.
I agree that from a point of view of an end user, no system can be trusted 100%. The addition of a backup software as the middle layer only makes it worse if the software is ill-devised. The only weapon against failures is hash verification. There are two types of hashes in Duplicacy, chunk hashes and file hashes. With chunk hashes we know for sure that a chunk we download is the same as what we uploaded. With the file hash we can be confident once we are able to restore a file with the correct file hash that we have restored correctly what was backed up. Of course, there can be some cases that may not be detected by hash verification (for instance, if there is a bug in reading the file during backup) but that is very unlikely.
towerbr Jan 21 7:37PM 2018
Continuing the tests ...
One of the goals of my use for Duplicati and Duplicacy is to back up large files (some Gb) that are changed in small parts. Examples: Veracrypt volumes, mbox files, miscellaneous databases, and Evernote databases (basically an SQLite file).
My main concern is the growth of the space used in the backend as incremental backups are performed.
I had the impression that Duplicacy made large uploads for small changes, so I did a little test:
I created an Evernote installation from scratch and then downloaded all the notes from the Evernote servers (about 4,000 notes, the Evernote folder was then 871 Mb, of which 836 Mb from the database).
I did an initial backup with Duplicati and an initial backup with Duplicacy.
Results:
Duplicati: 672 Mb 115 min
and
Duplicacy: 691 Mb 123 min
Pretty much the same, but with some difference in size.
Then I opened Evernote, made a few minor changes to some notes (a few Kb), closed Evernote, and ran backups again.
Results:
Duplicati (from the log):
BeginTime: 21/01/2018 22:14:41 EndTime: 21/01/2018 22:19:30 (~ 5 min) ModifiedFiles: 5 ExaminedFiles: 347 OpenedFiles: 7 AddedFiles: 2 SizeOfModifiedFiles: 877320341 SizeOfAddedFiles: 2961 SizeOfExaminedFiles: 913872062 SizeOfOpenedFiles: 877323330
and
Duplicacy (from the log):
Files: 345 total, 892,453K bytes; 7 new, 856,761K bytes File chunks: 176 total, 903,523K bytes; 64 new, 447,615K bytes, 338,894K bytes uploaded Metadata chunks: 3 total, 86K bytes; 3 new, 86K bytes, 46K bytes uploaded All chunks: 179 total, 903,610K bytes; 67 new, 447,702K bytes, 338,940K bytes uploaded Total running time: 01:03:50
Of course it jumped several chunks, but still uploaded 64 chunks of a total of 176!
I decided to do a new test: I opened Evernote and changed one letter of the contents of one note.
And I ran the backups again. Results:
Duplicati:
BeginTime: 21/01/2018 23:37:43 EndTime: 21/01/2018 23:39:08 (~1,5 min) ModifiedFiles: 4 ExaminedFiles: 347 OpenedFiles: 4 AddedFiles: 0 SizeOfModifiedFiles: 877457315 SizeOfAddedFiles: 0 SizeOfExaminedFiles: 914009136 SizeOfOpenedFiles: 877457343
and
Duplicacy (remembering: only one letter changed):
Files: 345 total, 892,586K bytes; 4 new, 856,891K bytes File chunks: 178 total, 922,605K bytes; 26 new, 176,002K bytes, 124,391K bytes uploaded Metadata chunks: 3 total, 86K bytes; 3 new, 86K bytes, 46K bytes uploaded All chunks: 181 total, 922,692K bytes; 29 new, 176,088K bytes, 124,437K bytes uploaded Total running time: 00:22:32
In the end, the space used in the backend (contemplating the 3 versions, of course) was:
Duplicati: 696 Mb Duplicacy: 1,117 Mb
That is, with these few (tiny) changes Duplicati added 24 Mb to the backend and Duplicacy 425 Mb.
Only problem: even with a backup so simple and small, in the second and third execution Duplicati showed me a "warning", but I checked the log and:
Warnings: []
Errors: []
It seems to me a behavior already known to Duplicati. What worries me is to ignore the warnings and fail to see a real warning.
Now I'm here evaluating the technical reason for such a big difference, thinking about how Duplicati and Duplicacy backups are structured. Any suggestion?
gchen Jan 21 10:32PM 2018
Interesting. I know the evernote data directory is just a big sqlite database and a bunch of very small files. The default chunk size in Duplicati is 100K, and 4M in Duplicacy. While 100K would be too small for Duplicacy, I wonder if you can run another test with the default size set to 1M:
duplicacy init -c 1M repository_id storage_url
Or even better, since it is a database, you can switch to the fixed-size chunking algorithm by calling this init command:
duplicacy init -c 1M -max 1M -min 1M repository_id storage_url
In fact, I would recommend this for backing up databases and virtual machines, as this is the default setting we used in Vertical Backup.
towerbr Jan 22 6:53AM 2018
OK! I deleted all backup files from the backend (Dropbox), I also deleted all local configuration files (preferences, etc.).
I ran the init command with the above parameters (second option, similar to Vertical Backup) and I'm running the new backup. As soon as it's finished I'll post the results here.
towerbr Jan 22 7:10AM 2018
I'm following up the backup and it's really different (as expected), since with the previous configuration it ran several packing commands and then an upload, and now it's almost 1:1, a packing and an upload.
But I noticed something: even with the chunk size fixed, they still vary in size, some have 60kb, some 500Kb, etc. None above 1Mb. Should not they all be 1024?
towerbr Jan 22 8:07AM 2018
Everything was going well until it started to upload the chunks for the database, so he stopped:
Packing Databases/.accounts
Uploaded chunk 305 size 210053, 9KB/s 1 day 03:08:51 0.8%
Packed Databases/.accounts (28)
Packing Databases/.sessiondata
Uploaded chunk 306 size 164730, 9KB/s 1 day 02:40:56 0.8%
Packed Databases/.sessiondata (256)
Packing Databases/lgtbox.exb
Uploaded chunk 307 size 231057, 9KB/s 1 day 01:58:44 0.8%
Uploaded chunk 308 size 28, 9KB/s 1 day 02:04:33 0.8%
Uploaded chunk 309 size 256, 9KB/s 1 day 02:08:27 0.8%
Uploaded chunk 310 size 1048576, 11KB/s 23:12:09 0.9%
Uploaded chunk 311 size 1048576, 12KB/s 20:56:24 1.0%
Uploaded chunk 312 size 1048576, 13KB/s 19:10:50 1.1%
Uploaded chunk 313 size 1048576, 14KB/s 17:36:14 1.3%
Uploaded chunk 314 size 1048576, 15KB/s 16:34:14 1.4%
...
...
Uploaded chunk 441 size 1048576, 61KB/s 03:23:18 15.9%
Uploaded chunk 442 size 1048576, 62KB/s 03:22:16 16.1%
Failed to upload the chunk 597ec712d6954c9d4cd2d64f38857e6b198418402d2aaef6f6c590cacb5af31d: Post https://content.dropboxapi.com/2/files/upload: EOF
Incomplete snapshot saved to C:\_Arquivos\Duplicacy\preferences\NOTE4_Admin_Evernote-dropbox/incomplete
I tried to continue the backup and:
Incomplete snapshot loaded from C:\_Arquivos\Duplicacy\preferences\NOTE4_Admin_Evernote-dropbox/incomplete
Listing all chunks
Listing chunks/
Listing chunks/48/
Listing chunks/8e/
...
Listing chunks/03/
Listing chunks/f4/
Listing chunks/2b/
Failed to list the directory chunks/2b/:
I tried again to run and now it's going ...
...
Skipped chunk 439 size 1048576, 19.77MB/s 00:00:38 15.8%
Skipped chunk 440 size 1048576, 19.91MB/s 00:00:37 15.9%
Skipped chunk 441 size 1048576, 20.05MB/s 00:00:37 16.1%
Uploaded chunk 442 size 1048576, 6.73MB/s 00:01:49 16.2%
Uploaded chunk 443 size 1048576, 4.45MB/s 00:02:44 16.3%
Uploaded chunk 444 size 1048576, 2.99MB/s 00:04:04 16.4%
...
towerbr Jan 22 11:46AM 2018
The new "initial" backup is completed, and it took much longer than with the previous setup:
Backup for C:_Arquivos\Evernote at revision 1 completed Files: 345 total, 892,586K bytes; 344 new, 892,538K bytes File chunks: 1206 total, 892,586K bytes; 764 new, 748,814K bytes, 619,347K bytes uploaded Metadata chunks: 3 total, 159K bytes; 3 new, 159K bytes, 101K bytes uploaded All chunks: 1209 total, 892,746K bytes; 767 new, 748,973K bytes, 619,449K bytes uploaded Total running time: 02:39:20
It ended up with 1206 file chunks (the previous was 176), which was expected.
Then I opened Evernote and it synchronized a note from the server (an article I had captured this morning), which lasted 2 seconds and added a few kb, see the log:
14:03:13 [INFO ] [2372] [9292] 0% Retrieving 1 note
14:03:13 [INFO ] [2372] [9292] 0% Retrieving note "Automação vai mudar a carreira de 16 ..."
14:03:13 [INFO ] [2372] [9292] 0% * guid={6a4d9939-8721-4fb5-b9d1-3aa6a045266f}
14:03:13 [INFO ] [2372] [9292] 0% * note content, length=0
14:03:13 [INFO ] [2372] [9292] 0% Retrieving resource, total size=31053
14:03:13 [INFO ] [2372] [9292] 0% * guid={827bb525-071c-40f3-9c00-1e82b60f4136}
14:03:13 [INFO ] [2372] [9292] 0% * note={6a4d9939-8721-4fb5-b9d1-3aa6a045266f}
14:03:13 [INFO ] [2372] [9292] 0% * resource data, size=31053
14:03:14 [INFO ] [2372] [7112] 100% Updating local note "Automação vai mudar a carreira de 16 ...", resource count: 4, usn=0
14:03:15 [INFO ] [2372] [7112] 100% * guid={6A4D9939-8721-4FB5-B9D1-3AA6A045266F}
14:03:15 [INFO ] [2372] [7112] 100% Updating local resource "363cd3502354e5dbd4e95e61e387afe2", 31053 bytes
The Evernote folder, which was like this:

becomed like this

So I ran a new backup with Duplicati:
BeginTime: 22/01/2018 16:07:50 EndTime: 22/01/2018 16:10:50 (~ 3 min) ModifiedFiles: 3 ExaminedFiles: 349 OpenedFiles: 5 AddedFiles: 2 SizeOfModifiedFiles: 877567112 SizeOfAddedFiles: 21073 SizeOfExaminedFiles: 914374437 SizeOfOpenedFiles: 877588213
and a new backup with Duplicacy:
Files: 346 total, 892,943K bytes; 4 new, 857,019K bytes
File chunks: 1207 total, 892,943K bytes; 74 new, 73,659K bytes, 45,466K bytes uploaded
Metadata chunks: 3 total, 159K bytes; 3 new, 159K bytes, 101K bytes uploaded
All chunks: 1210 total, 893,103K bytes; 77 new, 73,819K bytes, 45,568K bytes uploaded
Total running time: 00:14:16
A much better result than with the initial setup, but still, much longer runtime and twice as many bytes sent.
The question now is: can (should?) I push the limits and reconfigure chunks size to 100K?
gchen Jan 22 12:53PM 2018
In Duplicacy the chunk size must be a power of 2, so it has to 64K or 128K.
Generally a chunk size that is too small is not recommended for two reasons: it will create too many chunks on the storage, and the overhead of chunk transfer becomes significant. However, if the total size of your repository is less than 1G, a chunk size of 64K or 128K won't create too many chunks. The overhead factor can be mitigated by using multiple threads.
Unfortunately, Dropbox doesn't like multiple uploading threads -- it will complain about too many write requests if you attempt to do this. But, since in this test your main interest is the storage efficiency, I think you can just use a local storage and you can complete the run in minutes rather than hours.
Here is another thing you may be interested. Can you run Evernote on another computer and download the database there and then back up to the same storage? I'm not sure if the databases on two computers can be deduplicated -- it depends on how Evernote creates the sqlite database, but it may be worth a try.
towerbr Jan 22 2:30PM 2018
I think you can just use a local storage and you can complete the run in minutes rather than hours.
Nope, the idea is to do an off-site backup. I already do a local backup.
I'll try 128k with Dropbox...
Christoph Jan 22 2:41PM 2018
Very interesting results! Thangs a lot, towerbr, for the testing.
So the smaller chunk size leads to better results in the case of db files. But since the default chunk size is much bigger, I assume that for other types of backups, the smaller chunk size will create other problems? Does this mean I should exclude db files (does anyone have a regex?) from all my backups and create a separate backup for those (possibly one for each repository)? Not very convenient, but I guess we're seeing a clear downside of the duplicacy's killer feature, cross repository deduplication...
Another question concerning duplicacy's storage use:
In the end, the space used in the backend (contemplating the 3 versions, of course) was:
Duplicati: 696 Mb Duplicacy: 1,117 Mb
Unless I'm misunderstanding something, that difference will we significantly reduced, once you run a prune operation, right?
But then again, you will only save space at the cost of eliminating a revision compared to duplicati. So the original comparison is fair. Ironically, this means that duplicati is actually doing a (much) better job at deduplication between revisions...
Hm, this actually further worsens the space use disadvantage of duplicacy: I believe the original tests posted on the duplicati forum did not include multiple revisions. Now we know that the difference in storage use will actually increase exponentially over time (i.e. with every revision), especially when small changes are made in large files.
towerbr Jan 22 3:52PM 2018
Does this mean I should exclude db files (does anyone have a regex?) from all my backups and create a separate backup for those (possibly one for each repository)? Not very convenient...
Exact! In the case of this test, I think the solution would be to make an init with the normal chunk size (4M) for the Evernote folder with an exclude for the database, and an add with smaller chunk (128k maybe) to contemplate only the database via include.
The problem is that in the case of Evernote it is very easy to separate via include / exclude pattern because it is only one SQLite file. But for other applications, with multiple databases, it is not practical. And it's also not practical for mbox files, for example.
So, in the end, I would leave with only one configuration (128k) applied to the whole folder (without add), which is what I am testing now.
... the difference in storage use will actually increase exponentially over time (i.e. with every revision), especially when small changes are made in large files.
This is exactly my main concern.
Christoph Jan 22 4:40PM 2018
This is exactly my main concern.
Are you worried that it might be so and are testing it, or do you think it is so but are sticking to duplicacy for other reasons?
towerbr Jan 22 5:17PM 2018
Are you worried that it might be so and are testing it, or do you think it is so but are sticking to duplicacy for other reasons?
I'm testing Duplicacy and Duplicati for backing up large files. At the moment I have some jobs of each one running daily. I haven't decided yet.
In a very resumed way:
Duplicati has more features (which on the other hand exposes it to more failure points) and seems to me to deal better with large files (based on the performance of my jobs and this test so far). But the use of local databases and the constant warnings are the weak points.
Duplicacy seems to me a simpler and more mature software, with some configuration difficulty (init, add, storages, repositories, etc), but it starts to worry me about backups of large files.
gchen Jan 22 9:14PM 2018
Does this mean I should exclude db files (does anyone have a regex?) from all my backups and create a separate backup for those (possibly one for each repository)? Not very convenient...
I think an average chunk size of 1M should be good enough for general cases. The decision of 4M was mostly due to the considerations to reduce the number of chunks (before 2.0.10 all the cloud storage used a flat chunk directory) and to reduce the overhead ratio (single thread uploading and downloading in version 1). Now that we have a nested chunk structure for all storages, and multi-threading support, it perhaps makes sense to change the default size to 1M. There is another use case where 1M did much better than 4M: https://duplicacy.com/issue?id=5740615169998848
Duplicacy, however, was never to achieve the best deduplication ratio for a single repository. I knew from the beginning that by adopting a relatively large chunk size, we are going to lost the deduplication battle to competitors. But this is a tradeoff we have to make, because the main goal is the cross-client deduplication, which is completely worth the lose in deduplication efficiency on a single computer. For instance, suppose that you need to back up your Evernote database on two computers, then the storage saving brought by Duplicacy already outweighs the wasted space due to a much larger chunk size. Even if you don't need to back up two computers, you can still benefit from this unique feature of Duplicacy -- you can seed the initial backup on a computer with a faster internet connection, and then continue to run the regular backups on the computer with a slower connection.
I also wanted to add that the variable-size chunking algorithm used by Duplicacy is actually more stable than the fixed-size chunking algorithm in Duplicati, even on a single computer. Fixed-size chunking is susceptible to deletions and insertions, so when a few bytes are added to or removed from a large file, all previously split chunks after the insertion/deletion point will be affected due to changed offsets, and as a result a new set of chunks must be created. Such files include dump files from databases and unzipped tarball files.
towerbr Jan 23 7:01AM 2018
you can seed the initial backup on a computer with a faster internet connection, and then continue to run the regular backups on the computer with a slower connection.
This is indeed an advantage. However, to take advantage of it, the files must be almost identical on both computers, which does not apply to Evernote. But there are certainly applications for this kind of use.
towerbr Jan 23 7:24AM 2018
The new initial backup with 128k chunks is finished. Took several hours and was interrupted several times, but I think it's Dropbox's "fault".
It ended like this:
Files: 348 total, 892,984K bytes; 39 new, 885,363K bytes
File chunks: 7288 total, 892,984K bytes; 2362 new, 298,099K bytes, 251,240K bytes uploaded
Metadata chunks: 6 total, 598K bytes; 6 new, 598K bytes, 434K bytes uploaded
All chunks: 7294 total, 893,583K bytes; 2368 new, 298,697K bytes, 251,674K bytes uploaded
Interesting that the log above shows a total size of ~890Mb but the direct verification with Rclone in the remote folder shows 703Mb (?!).
What I'm going to do now is to run these two jobs (Duplicati and Duplicacy) for a few days of "normal" use and follow the results in a spreadsheet, so I'll go back here and post the results.
gchen Jan 23 10:07AM 2018
The new initial backup with 128k chunks is finished. Took several hours and was interrupted several times, but I think it's Dropbox's "fault".
I think we should retry on EOF when Dropbox closes the connection.
Interesting that the log above shows a total size of ~890Mb but the direct verification with Rclone in the remote folder shows 703Mb (?!).
The original size is 893Mb and what Rclone shows is the total size after compression and encryption.
towerbr Jan 23 10:34AM 2018
I think we should retry on EOF when Dropbox closes the connection.
I agree, that's what I did in this last backup and in the previous one (with 1M chunk). If the attempt was made shortly after the interruption Dropbox would not accept, but if you wait a few minutes and run the command the upload worked again.
The original size is 893Mb and what Rclone shows is the total size after compression and encryption.
Ah, understood! I'm using Rclone in the script right after the backups, to obtain the size of the two remote folders.
It's a shame that neither Dropbox nor Google Drive provides an easy way to view the size of a folder. In Dropbox you have to do several steps in the web interface, and Google drive is even worse, with the view by the quota.
Christoph Jan 23 4:07PM 2018
I think an average chunk size of 1M should be good enough for general cases.
So by "average chunk size" you mean that it should not be 1M fixed chunks? Is there a way of changing the default chunk size on a specific computer?
The new initial backup with 128k chunks is finished.
BTW: these are fixed size chunks, right?
It ended like this:
Files: 348 total, 892,984K bytes; 39 new, 885,363K bytes File chunks: 7288 total, 892,984K bytes; 2362 new, 298,099K bytes, 251,240K bytes uploaded Metadata chunks: 6 total, 598K bytes; 6 new, 598K bytes, 434K bytes uploaded All chunks: 7294 total, 893,583K bytes; 2368 new, 298,697K bytes, 251,674K bytes uploaded
So what exactly does this mean in terms of comparison with both duplicati and duplicacy with 1MB chunks?
Or is it rather the values from Rclone that should be compared?
Or is the initial backup size not dependent on chunk size all?
towerbr Jan 23 6:12PM 2018
BTW: these are fixed size chunks, right?
Yes, I used the command: duplicacy init -e -c 128K -max 128K -min 128K ...
So what exactly does this mean in terms of comparison with both duplicati and duplicacy with 1MB chunks?
Gilbert said that Duplicati uses 100k (fixed) chunks.
In my tests with Duplicacy above:
1st setting (4M chunks): 176 chunks - initial upload: 02:03
2nd setting (1M chunks): 1206 chunks - initial upload: 02:39
3rd setting (128k chunks): 7288 chunks - initial upload: several hours
Is this your question?
Or is the initial backup size not dependent on chunk size all?
The smaller the size of the chunks, the greater the number of chunks. Then the number of upload requests is also greater, which makes total uploading more time-consuming. And in the specific case of Dropbox, it seems to "dislike" so many requests.
Christoph Jan 24 5:48PM 2018
Is this your question? No, I was just trying to compare initial storage use in all the different scenarios we have so far. Something like:
duplicati (default setting) uses w GB duplicacy (4M chunks, variable) uses x GB duplicacy (1M chunks) uses y GB duplicacy (128k chunks) uses z GB
@gchen: since the chunk size turns out to be such a crucial decision at the very beginning and which cannot be changed unless you want to start uploading from scratch, could you provide some more information about the trade offs involved when choosing chunk size. So for example:, what difference will it make if choose 1M vs 512k vs 128k chunksize and whether I choose fixed or variable chunk size?
towerbr Jan 24 7:23PM 2018
duplicati (default setting) uses w GB duplicacy (4M chunks, variable) uses x GB duplicacy (1M chunks) uses y GB duplicacy (128k chunks) uses z GB
So I think that's this you are asking for:
Duplicati: initial upload: 01:55 - 672 Mb
Duplicacy:
1st setting (4M chunks, variable): 176 chunks - initial upload: 02:03 - 691 Mb
2nd setting (1M chunks, fixed): 1206 chunks - initial upload: 02:39 - (I didn't measure with Rclone)
3rd setting (128k chunks, fixed): 7288 chunks - initial upload: several hours - 703 Mb
gchen Jan 25 2:21PM 2018
Dropbox is perhaps the least thread friendly storage, even after Hubic (which is the slowest).
I ran a test to upload 1GB file to Wasabi. Here is the result with the default 4M chunk size (with 16 threads):
Uploaded chunk 201 size 2014833, 37.64MB/s 00:00:01 99.2%
Uploaded chunk 202 size 7967204, 36.57MB/s 00:00:01 100.0%
Uploaded 1G (1073741824)
Backup for /home/gchen/repository at revision 1 completed
Files: 1 total, 1048,576K bytes; 1 new, 1048,576K bytes
File chunks: 202 total, 1048,576K bytes; 202 new, 1048,576K bytes, 1,028M bytes uploaded
Metadata chunks: 3 total, 15K bytes; 3 new, 15K bytes, 14K bytes uploaded
All chunks: 205 total, 1,024M bytes; 205 new, 1,024M bytes, 1,028M bytes uploaded
Total running time: 00:00:28
Almost no differences with the chunk size set to 1M:
Uploaded chunk 881 size 374202, 36.49MB/s 00:00:01 99.7%
Uploaded chunk 880 size 2277351, 36.57MB/s 00:00:01 100.0%
Uploaded 1G (1073741824)
Backup for /home/gchen/repository at revision 1 completed
Files: 1 total, 1048,576K bytes; 1 new, 1048,576K bytes
File chunks: 882 total, 1048,576K bytes; 882 new, 1048,576K bytes, 1,028M bytes uploaded
Metadata chunks: 3 total, 64K bytes; 3 new, 64K bytes, 55K bytes uploaded
All chunks: 885 total, 1,024M bytes; 885 new, 1,024M bytes, 1,028M bytes uploaded
Total running time: 00:00:29
But 128K chunk size is much slower:
Uploaded chunk 6739 size 127411, 14.63MB/s 00:00:01 99.9%
Uploaded chunk 6747 size 246758, 14.42MB/s 00:00:01 100.0%
Uploaded 1G (1073741824)
Backup for /home/gchen/repository at revision 1 completed
Removed incomplete snapshot /home/gchen/repository/.duplicacy/incomplete
Files: 1 total, 1048,576K bytes; 1 new, 1048,576K bytes
File chunks: 6762 total, 1048,576K bytes; 6762 new, 1048,576K bytes, 1,028M bytes uploaded
Metadata chunks: 5 total, 486K bytes; 5 new, 486K bytes, 401K bytes uploaded
All chunks: 6767 total, 1,024M bytes; 6767 new, 1,024M bytes, 1,028M bytes uploaded
Total running time: 00:01:11
Christoph Jan 25 2:38PM 2018
OK, thanks for sharing! So it's as I suspected at some point:
Or is the initial backup size not dependent on chunk size all?
No, not really. But now we have that clarified: The (only) disadvantage of the larger chunk files is in subsequent backups of files (esp. large ones) when they are changed. Concretely: with the default settings (4MB chunks), duplicacy went from 691 MB to 1117 MB within three (very minor) revisions, while duplicati went from 672 MB to 696 MB with the same 3 revisions. We don't know the exact figures for the test with 1MB chunks test, but we assume the waste of space was reduced.
So now we're anxiously awaiting your results to see how much improvement we can get out of 128kb chunks.
Regarding another extreme scenario: lots of small files changed often, how would that be affected by small vs large and by variable vs fixed chunk size? What can be said about that without running tests?
gchen Jan 25 9:30PM 2018
(Copied from the discussion at https://github.com/gilbertchen/duplicacy/issues/334#issuecomment-360641594):
There is a way to retrospectively check the effect of different chunk sizes on the deduplication efficiency. First, create a duplicate of your original repository in a disposable directory, pointing to the same storage:
mkdir /tmp/repository
cd /tmp/repository
duplicacy init repository_id storage_url
Add two storages (ideally local disks for speed) with different chunk sizes:
duplicacy add -c 1M test1 test1 local_storage1
duplicacy add -c 4M test2 test2 local_storage2
Then check out each revision and back up to both local storages:
duplicacy restore -overwrite -delete -r 1
duplicacy backup -storage test1
duplicacy backup -storage test2
duplicacy restore -overwrite -delete -r 2
duplicacy backup -storage test1
duplicacy backup -storage test2
Finally check the storage efficiency using the check command:
duplicacy check -tabular -storage test1
duplicacy check -tabular -storage test2
towerbr Jan 26 6:35AM 2018
Dropbox is perhaps the least thread friendly storage, even after Hubic (which is the slowest).
I completely agree, but i have the space there "for free". Dropbox has a "soft limit" of 300,000 files, and I reached that limit (of files) with just 300 Gb. So the remaining 700 Gb were wasted, and i decided to use for backup.
For professional reasons I can not cancel the Dropbox account now, but in the future I'm planning to move backups to Wasabi or other (pCloud looks interesting also). I've used Backblaze B2 in the past but the features of the web interface are limited, in my opinion.
Jonnie Jan 27 7:20AM 2018
Dropbox has a "soft limit" of 300,000 files
I didn't know this, but here is their explanation: https://www.dropbox.com/help/space/file-storage-limit
Out of curiosity, does anyone know if this refers only to the Dropbox Application and it's Sync behavior, or to the API too? I was thinking about using Dropbox Pro to store a few TB, but won't bother if there is a file limit, because Duplicacy will chew that up pretty quick.
It sounds like you can store more than 300,000 files, but it becomes an issue if you are trying to Sync those with the App, does that sound right?
towerbr Jan 28 4:02PM 2018
It sounds like you can store more than 300,000 files, but it becomes an issue if you are trying to Sync those with the App, does that sound right?
Yes, it's exactly like that.I have more than 300,000 files there, but I only sync part of them.
does anyone know if this refers only to the Dropbox Application and it's Sync behavior, or to the API too?
That's a good question!
towerbr Jan 28 4:04PM 2018
.........
towerbr Jan 28 5:18PM 2018
Well, this is probably my final test with the Evernote folder, and some results were strange, and i really need your help to understand what happened at the end...
Some notes:
Upload and time values were obtained from the log of each software.
Duplicati:
bytes uploaded = “SizeOfAddedFiles”
upload time = “Duration”
Duplicacy:
bytes uploaded = “bytes uploaded” in log line “All chunks”
upload time = “Total running time”
Rclone was used to obtain the total size of each remote backend.
In the first three days I used Evernote normally (adding a few notes a day, a few kb), the result was as expected:
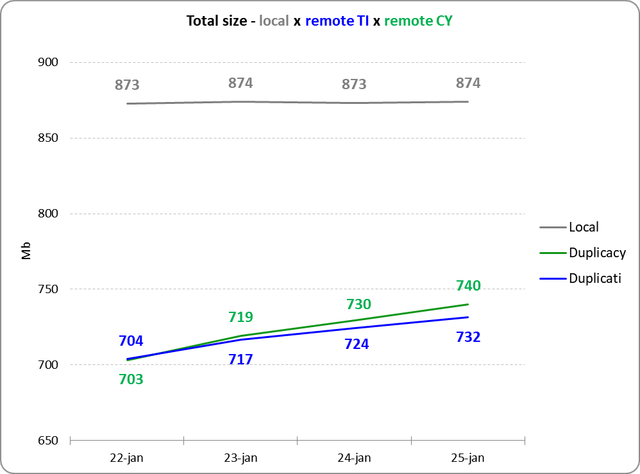
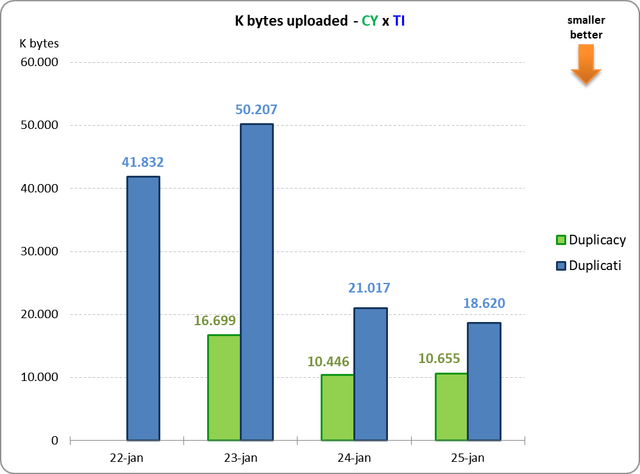
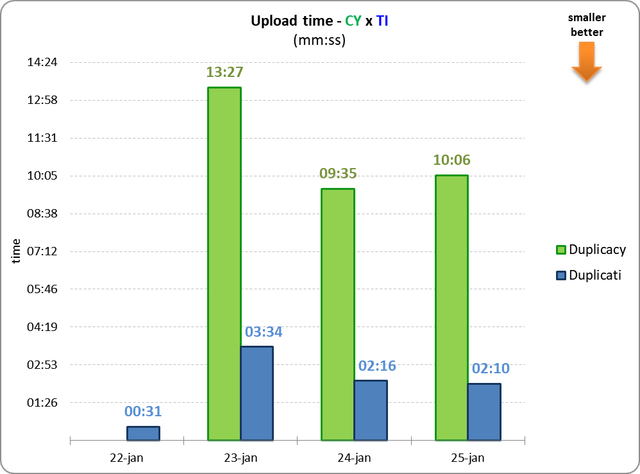
BUT, this is the first point I didn't understand:
1) How does the total size of Duplicacy backend grows faster if daily uploading is smaller (graph 1 x graph 2)?
Then on 26th I decided to organize my tags in Evernote (something I already wanted to do). So I standardized the nomenclature, deleted obsolete tags, rearranged, etc. That is, I didn' t add anything (bytes), but probably all the notes were affected.
And the effect of this was:
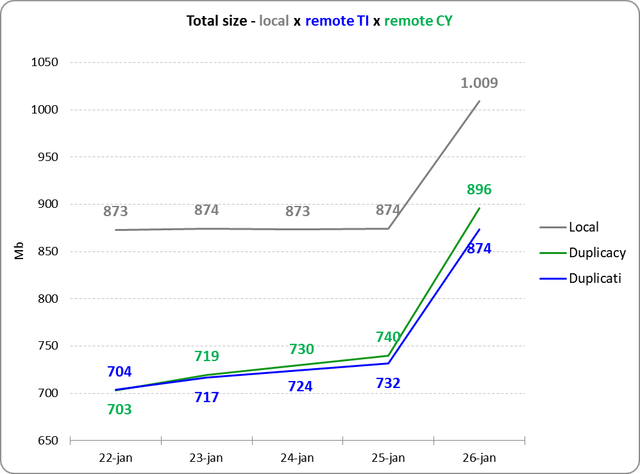
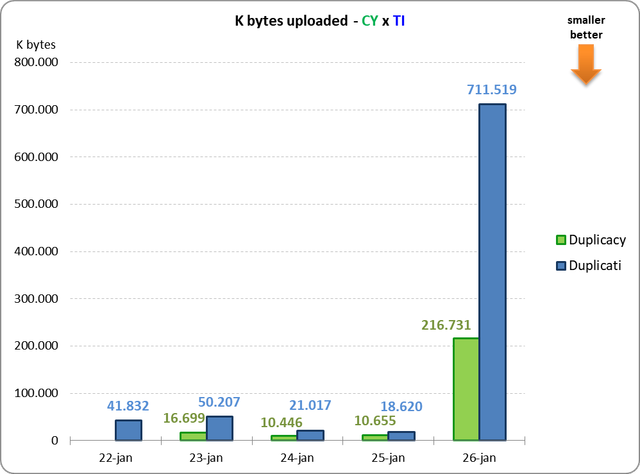
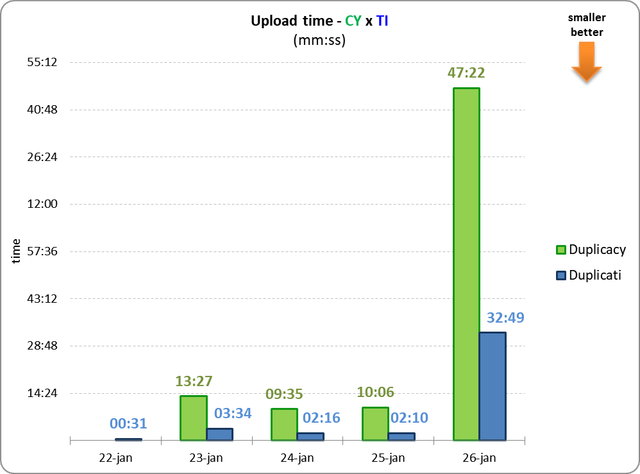
That is, something similar to the first few days, just greater.
Then, on day 27, I ran an internal Evernote command to "optimize" the database (rebuild the search indexes, etc.) and the result (disastrous in terms of backup) was:
(and at the end there are the other points for which I would like your help to understand)
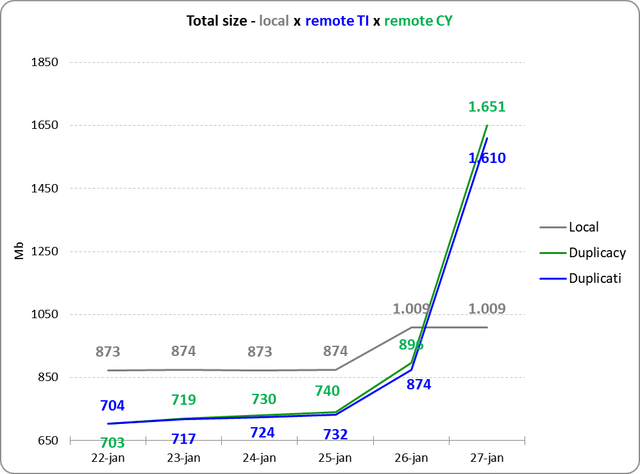
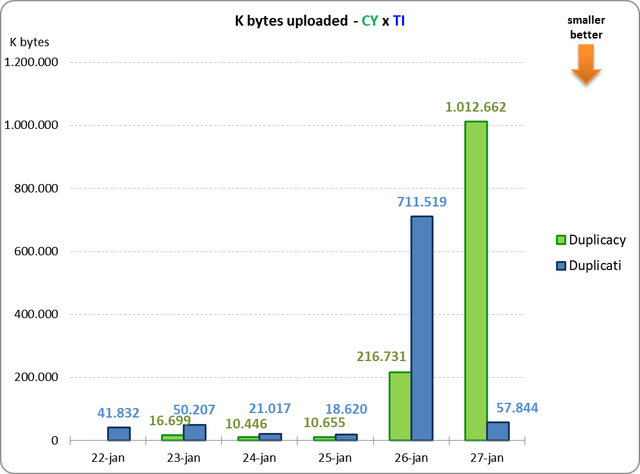
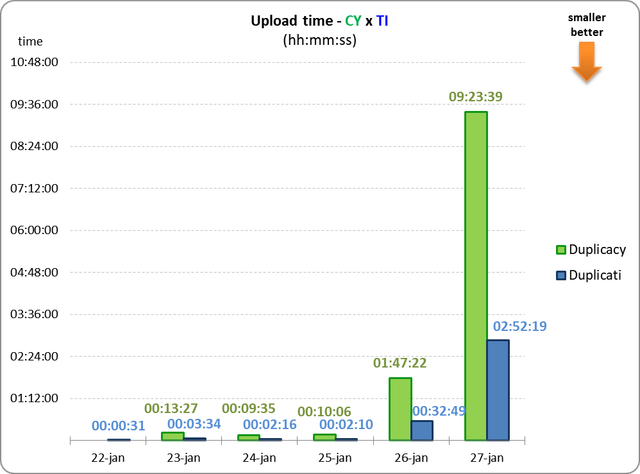
2) How could Duplicati upload have been so small (57844) if it took almost 3 hours?
3) Should I also consider the “SizeOfModifiedFiles” Duplicati log variable?
4) If the upload was so small, why the total size of the remote has grown so much?
5) Why did Duplicacy last upload take so long? Was it Dropbox's fault?
I would like to understand all these doubts because this was a test to evaluate the backup of large files with minor daily modifications, and the real objective is to identify the best way to backup a set of 20Gb folders with mbox files, some with several Gb , others with only a few kb.
I look forward to hearing from you all.
(P.S.: Also posted on the Duplicati forum)
gchen Jan 28 8:00PM 2018
1) How does the total size of Duplicacy backend grows faster if daily uploading is smaller (graph 1 x graph 2)?
4) If the upload was so small, why the total size of the remote has grown so much?
I'm puzzled too. Can you post a sample of those stats line from Duplicacy here?
5) Why did Duplicacy last upload take so long? Was it Dropbox's fault?
This is because the chunk size is too small, so a lot of overhead is spent on other things like establishing the connections and sending the request headers etc, rather than on sending the actual data. Since the chunk size of 128K didn't improve the deduplication efficiency by too much, I think 1M should be the optimal value for your case.
towerbr Jan 28 10:03PM 2018
I'm puzzled too. Can you post a sample of those stats line from Duplicacy here?
Sure! So for that:
You have the full log here.
gchen Jan 28 10:38PM 2018
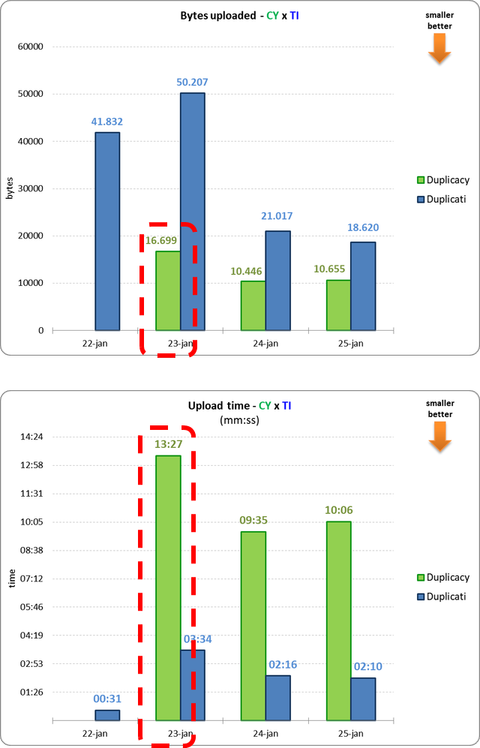
That is actually 16,699K bytes.
All chunks: 7314 total, 895,850K bytes; 236 new, 29,529K bytes, 16,699K bytes uploaded
Then, on day 27, I ran an internal Evernote command to "optimize" the database (rebuild the search indexes, etc.) and the result (disastrous in terms of backup) was:
I wonder if the variable-size chunking algorithm can do better for this kind of database rebuild. If you want to try, you can follow the steps in one of my posts above to replay the backups -- basically restoring from existing revisions in your Dropbox storage and then back up to a local storage configured to use the variable-size chunking algorithm.
towerbr Jan 29 5:24AM 2018
That is actually 16,699K bytes.
Sorry, the graphs titles are wrong, I will correct them ASAP.
But the question remains: 1) How does the total size of Duplicacy backend grows faster if daily uploading is smaller (graph 1 x graph 2)?
I wonder if the variable-size chunking algorithm can do better for this kind of database rebuild.
But it has to support both situations: small daily changes and these kind of "rebuilds".
Switching to variable chunks will not make us to return to the beginning of the tests?
towerbr Jan 29 8:20AM 2018
Sorry, the graphs titles are wrong, I will correct them ASAP.
Graphs have been fixed!
gchen Jan 29 1:51PM 2018
1) How does the total size of Duplicacy backend grows faster if daily uploading is smaller (graph 1 x graph 2)?
I guess that is because Duplicati compacts chunks of 100K bytes into zip files of 50M bytes by default, so the compression works better.
Switching to variable chunks will not make us to return to the beginning of the tests?
You can. And that is what I meant by "replay the backups". You can create a new repository with the same repository id and storage url, but add a new storage with -c 128k being the only argument, then restore the repository to the revision before the database rebuild, back up to the additional storage, and finally restore the repository to the revision after the database rebuild and back up to the additional storage. The additional storage can be only your local disk to save running time.
towerbr Jan 29 4:25PM 2018
I guess that is because Duplicati compacts chunks of 100K bytes into zip files of 50M bytes by default, so the compression works better.
Maybe. However, in my case, I set up Duplicati "volumes" for 5M.
You can...
What I meant is that doing a new backup with 1M variable chunks will not be equivalent to the first few tests above (Jan 22 6:53AM)? That is, it may even work well for rebuild, but will cause problems with minor database changes.
Christoph Jan 29 4:51PM 2018
I know there are a lot of mysterious things going on, but one thing seems to be clear: with 128kB chunks, we are not seeing an increasing gap between duplicati storage use and duplicacy storage use, right?
It also seems clear/confirmed, that a 128kB chunk size is not a good idea due to speed. Generally, I would say: I don't care about speed because the backup runs in the background and it doesn't matter how long it takes. But the uploads on 26 and 27 January made me change my mind (if not the one on the 26th then definitely the one on the 27th). If backups can take 9 hours even though not a lot of data have been added to the repository, that means that, at least on my home computer, chances are that it will not complete the same day that it started and since I don't turn on my home PC every day, it may well take a few days, perhaps even a week, until the backup completes, leading to all kinds of possible issues. Right?
towerbr Jan 29 4:55PM 2018
I agree with both conclusions!
towerbr Jan 30 1:44PM 2018
Gilbert, I'll do the tests with local backup of Evernote you mentioned, but only in a few days, now I’m a little busy. For now, the two backup jobs are suspended to avoid data collection problems out of controlled conditions.
I'm also thinking of doing a test with local storage for the mbox files I mentioned above. I intend to do this test with 1M variable chunks, I understood that should be the best option, right?
gchen Jan 30 9:52PM 2018
Yes, 1M variable chunks should be fine. I suspect fixed-size chunking would work poorly for mbox files, because, if I understand it correctly, a mbox file is just a number of emails concatenated together so a deleted or added email would cause every chunk to be different.
Christoph Jan 31 1:57PM 2018
Duplicacy seems to me a ... more mature software
I'm not so sure about that anymore: https://github.com/gilbertchen/duplicacy/issues/346 (This is very serious, IMHO)
towerbr Jan 31 5:04PM 2018
Interesting ... following there...
gchen Jan 31 10:41PM 2018
I agree that it is really bad if directories supposed to be backed up are not included in the backup.
But, when Duplicacy failed to list a directory, it will give out warnings like these (copied from the github issue):
Subdirectory dir1/ cannot be listed
Subdirectory dir2/ cannot be listed
File file1 cannot be opened
Backup for /Users/chgang/AcrosyncTest/repository at revision 2 completed
2 directories and 1 file were not included due to access errors
I can't think of a reason other than permission issues that can cause Duplicacy to skip a directory or file without giving out such warnings.
You may be interested to check out this thread updated today: https://duplicacy.com/issue?id=5670052883857408. A user is seeing a lot of "Failed to read symlink" messages reported by Duplicacy, whereas Crashplan would just silently back up the empty folders without backing up any files there.
towerbr Feb 6 12:55PM 2018
I decided to set up a repository in GitHub to put the results of the tests I'm executing. For anyone interested: link